miSsuS
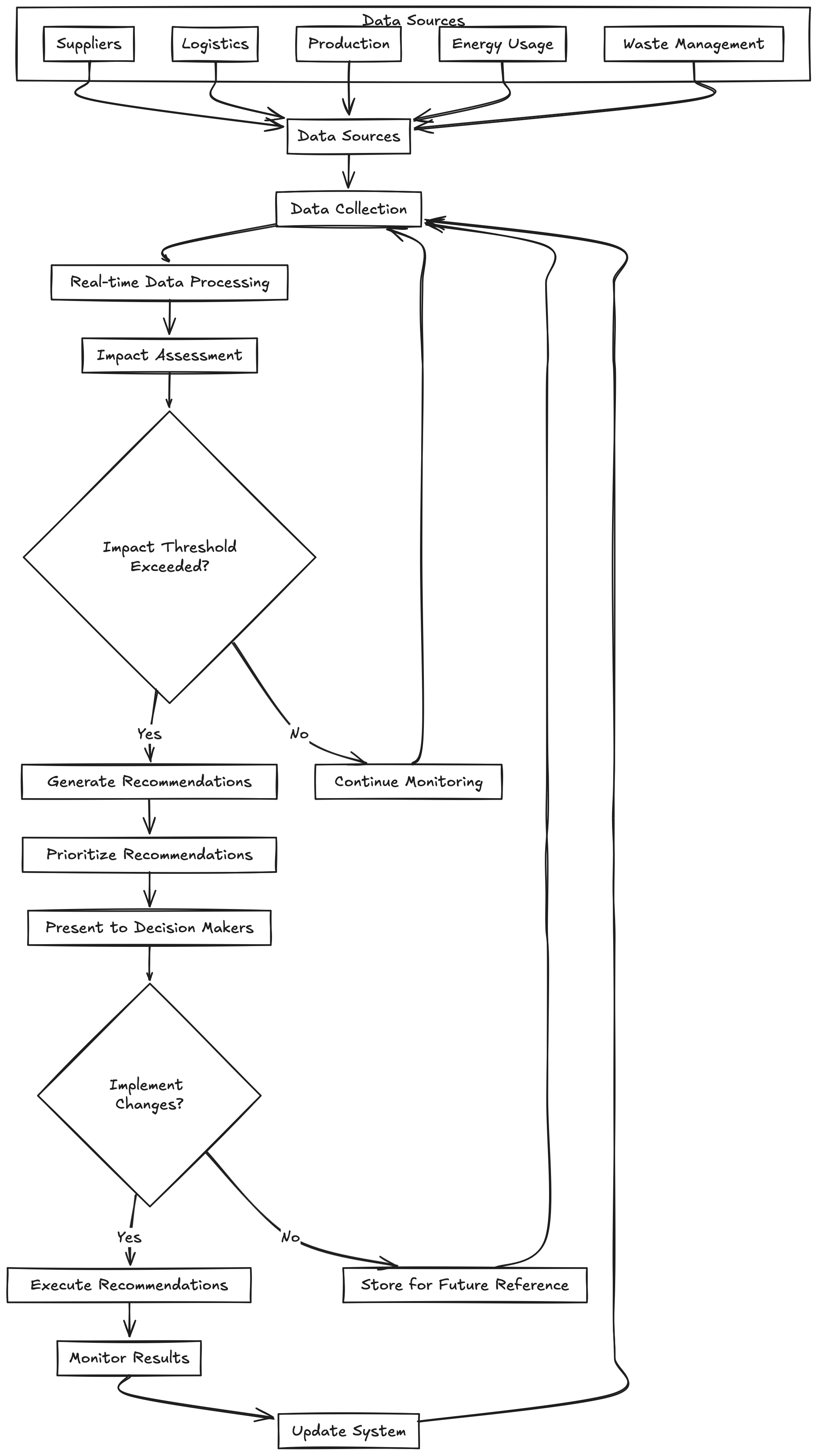
Template architecture for a data collection, assessment, and recommendation engine.Background
"Sustainability" has become a critical focus for businesses, especially within the consumer product industries, as they face increasing pressure from consumers, regulatory bodies, and environmental organizations to reduce their environmental impact. The supply chain of a company is often a significant contributor to that company’s carbon footprint and environmental degradation, including the use of raw materials, the production of those materials, transportation emissions, waste generation, and even their customer's usage and eventual disusage.
I put "sustainability" in quotes because the definition varies. In the context of miSsuS, sustainability is anywhere between net-zero and climate positive while also maintaining or improving a companies bottom line. Simply put, being sustainable means producing a good while not harming the environemnt and still being able to maintain or improve profits.
With this in mind I tried to develop miSsuS with a recommendation engine that would help businesses in different industries assess the environmental impact of their supply chains and receive actionable recommendations. miSsusS was to analyze data in real-time from multiple sources (e.g., suppliers, logistics, production) and offer suggestions for reducing waste, emissions, and the consumption of natural resources. The ultimate goal was to enable businesses to optimize their supply chains to be more sustainable while maintaining profitability.
That being said, a lot happened, and I wasn't able to take SIVENTH and miSsuS where I wanted it to go. The below an overview of the architecture and tech stack I planned on implementing. I've tried to summarize the implementation steps in the hopes that if not myself, then someone else will be able to build what I could not.
Methodology
The system architecture for miSsuS was to consist of the following:
Overview
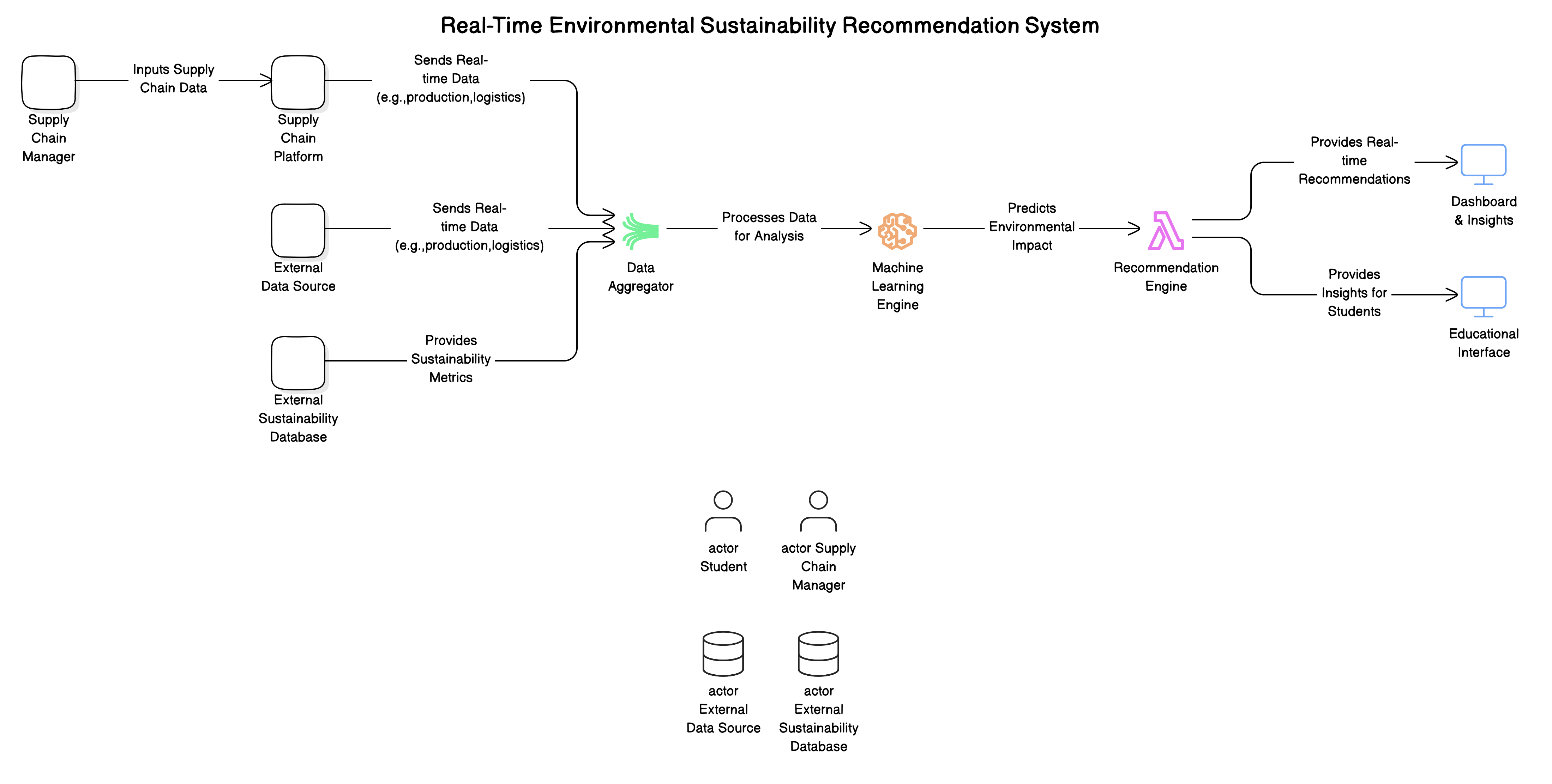
- Supply Chain Assessment(miSsuS): Platform where supply chain managers and other related participants input relevant operational data.
- Data Aggregator*: Collects real-time data from various points in the supply chain, including logistics, supplier information, and production details.
- Machine Learning Engine*: Analyzes the aggregated data using machine learning models to identify patterns in carbon footprint, waste, and energy usage.
- Recommendation Engine**: Uses the processed data to generate actionable sustainability recommendations, for exmaple:
- Choosing alternative fertilization methods.
- Choosing suppliers with lower environmental impact.
- Reducing emissions by optimizing routes.
- Creating buy-back programs for certain products.
- Dashboard & Insights(miSsuS): Provides a real-time dashboard for supply chain managers to view sustainability metrics, track and apply recommendations.
- Educational Interface(miSsuS): A specialized interface for students to access real-time supply chain data and insights for educational purposes.
- External Sustainability Database**: Integration with external databases providing environmental certification data, emissions standards, and other sustainability metrics.
**: I started development but was unable to make production ready.
Data Flow
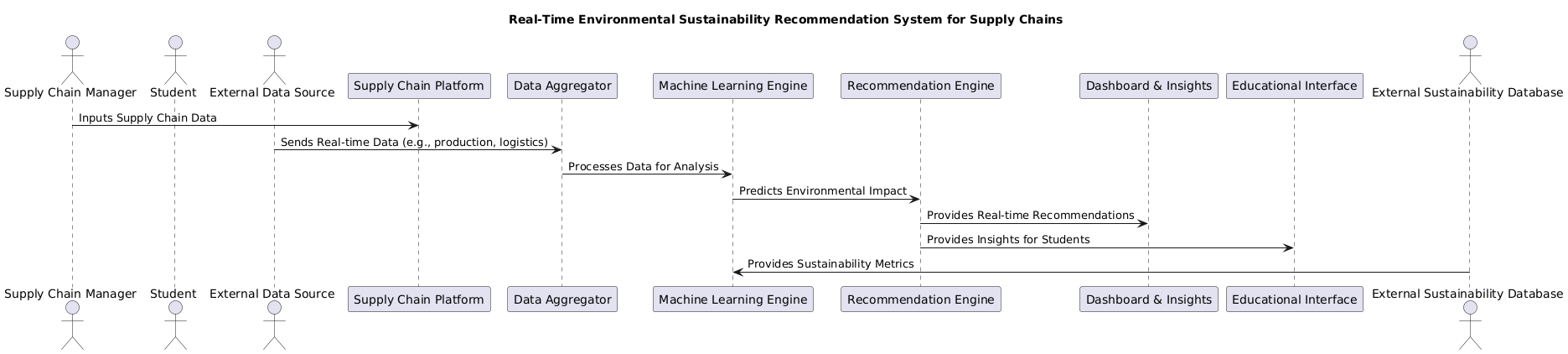
In terms of the overall data flow, this is how I envisioned things. Some of this I had begun implementing; others (mainly the machine learning related compontnents) I didn't get around to.
- Data Collection:
- miSsuS would gather data from various sources, including supplier data, production information, and logistics details.
- The Data Aggregator would continuously collect real-time data streams from these sources to keep track of any changes in operations.
- Data Processing:
- The Machine Learning Engine that uses historical and real-time data to identify patterns and predict the environmental impact of the current supply chain.
- This includes analyzing green house gas emissions, energy consumption, waste generation, and water usage.
- Recommendation Generation:
- The Recommendation Engine takes the results from the Machine Learning Engine and applies predefined rules and models to provide recommendations. For example:
-
Suggesting more sustainable materials from a different supplier.
If I made it to the point where we were tracking inventory, the engine could recommend obtaining materials from other locatins owned by the user. -
Identifying more energy-efficient transportation routes.
-
Highlighting inefficiencies in production that increase waste.
-
- Insights & Action:
- The recommendations are sent to the miSsuS dashboard, allowing supply chain managers to make real-time decisions.
- Simultaneously, the data is shared with the miSsuS educational interface, where students can interact with the platform, learn about supply chains, and observe the system's recommendations.
Algorithms and Models
-
Feature Extraction:
The system extracts important features from supply chain data, such as:
- Sustainability related metrics
- Industry best practices
- Yield rate and production efficieny
- Logistics GHG emissions per shipment
- Energy consumption per product unit
- Waste generated during production processes
- Water used/reused during production processes
-
Machine Learning Models:
-
Supervised Learning: Trains on historical data to predict environmental outcomes, such as energy usage or emissions based on supply chain decisions.
-
Unsupervised Learning: Trains on data mined from various sources in order to identify possible patterns within similar or synergistic supply chains. There's just too much data to not.
-
Reinforcement Learning: Adjusts recommendations dynamically based on feedback from implemented changes in the supply chain (i.e., closed-loop learning).
With all of the above I consider using synthetic data to also be a valid option specifically because supply chains are vast organisms with very defined practices. Even if there isn't enough data for the international motorboat industry, because of similarities with the automotive industry we can derive synthetic data for it (is my thought process).
- Sustainability Scoring:
- The system assigns a sustainability score to each supply chain process, factoring in the environmental impact, efficiency, and cost. This score helps prioritize recommendations.
- Decision Trees and Optimization Algorithms:
- Decision Trees: Used to categorize supply chain decisions into high-impact or low-impact actions in terms of sustainability.
- Optimization: The system employs optimization algorithms (e.g., linear programming) to find the most sustainable solution within a given set of constraints, such as industry best practices, cost, or production time.
Implementation
The implementation of the miSsuS System would have involved several stages, from data integration to deploying machine learning models and building user interfaces. Unfortunately, as I said above, I only made it as far as manual implementations and the associated user interfaces. Below is a step-by-step guide on how I planned to implement miSsuS in an ideal world.
1. Data Integration and Collection
-
Step 1: Set up data pipelines to integrate real-time data from supply chain sources (e.g., suppliers, logistics, production units).
- Use ETL (Extract, Transform, Load) tools like Apache NiFi or AWS Glue to aggregate data from various sources.
- For real-time data, use event streaming platforms like Apache Kafka or AWS Kinesis to continuously ingest data from supply chain operations.
-
Step 2: Integrate external sustainability data (e.g., emissions databases, certification programs) using APIs from external sources like Carbon Trust or CDP (Carbon Disclosure Project). It will depend on your use case and context.
This is essentially where I got stuck. Finding relevant data and modifying it to fit a schema that I could properly apply AWS Glue to and make sense of. I wasn't able to find a consistent souce of truth so I resolved to map industry best practices and then generate synthetic data from early user responses. If you have better resources you'll have access to high quality data that you can parse and apply to your machine learning models.
2. Machine Learning Model Development
- Step 1: Build a feature extraction pipeline to extract relevant sustainability-related features from the data (e.g., carbon footprint, energy consumption).
- Tools like Python’s Pandas, NumPy, and Scikit-learn can be used for preprocessing and feature engineering.
- Step 2: Train the machine learning models using historical data and synthetic data to predict environmental impacts.
- Supervised learning models such as Random Forest, Gradient Boosting, or Neural Networks will be useful for prediction.
- Unsupervised learning models can be useful when trying to parse large quantities of data.
- Reinforcement learning can be applied for continuous model improvement.
- Use frameworks such as TensorFlow, PyTorch, or Scikit-learn.
- Step 3: Deploy models using a cloud-based platform like AWS Sagemaker, Azure Machine Learning, or Google Cloud AI.
3. Recommendation Engine
- Step 1: Develop the recommendation engine using optimization algorithms and rule-based logic to generate actionable insights.
- For consumer product industries, industry best practices is a good starting point.
- Tools like PuLP or OR-Tools can be used for optimization and decision-making processes.
- Step 2: Integrate the recommendation engine with the machine learning predictions to deliver real-time suggestions on how to reduce environmental impact.
-
This can be done using a microservices architecture where the recommendation engine is exposed as an API for other services to consume.
This is a good time to mention that all components should be modular and leverage as much cloud/stateless services as possible.
-
4. Dashboard and User Interfaces
- Step 1: Build the Dashboard for supply chain managers using frontend frameworks like React.js, Angular, or Vue.js, and backend services like Node.js or Python (Django/Flask).
- Visualization tools like D3.js or Plotly can be used to display sustainability metrics, environmental impact graphs, and recommendations in real time.
- Step 2: Develop the Educational Interface with similar frontend technologies to provide students with access to real-time supply chain data and insights.
- This interface should be interactive, enabling students to explore different scenarios and see how the system generates recommendations.
5. Deployment and Scaling
- Step 1: Deploy the system using cloud platforms like AWS, Azure, or Google Cloud.
- Use Kubernetes or Docker for containerization and easy scalability.
- For databases, use cloud-based databases like Amazon RDS (relational data) or Amazon DynamoDB (NoSQL).
- Step 2: Set up autoscaling and monitoring to ensure the system can handle high transaction volumes and supply chain data in real-time without degradation in performance.
- Monitoring tools like Prometheus or AWS CloudWatch can be used to track the system’s performance.
6. Continuous Learning and Feedback Loop
- Step 1: Implement a feedback loop where the system continuously learns from new data and adjusts its predictions and recommendations.
- Integrate feedback from implemented sustainability changes to fine-tune the machine learning models (reinforcement learning).
- Step 2: Schedule periodic retraining of machine learning models based on updated supply chain data to ensure that the system adapts to evolving industry practices.
Summary
Hopefully the above helps someone with their own system for data collection, assessment, and recommendation engine. Even if you don't build something with the intention of tackling a sustainability issue, I think the above architecture is reusable for any recommendation type system. Collect data > model data > analyze data > create recommendations.
Their area also alternatives to the listed tools, frameworks, and services. Personally for miSsuS, I leveraged React.js (Next) for the frontend, AWS Amplify with Appsync & GraphQL for the backend, and was beginning to use TensorFlow for the modeling, and AWS Glue for ETL. I had intended to explore Sagemaker but along with other things, I just didnt have the time to get around to it.
Either way, there are a lot of options, good luck.